
Stata有一些导出统计、回归结果的工具,比如outreg2, asdoc, esttab,但这几个工具对中文的支持都不好,导出rtf文件里的中文会变成乱码。这是由于它们用了UTF-8编码导出,rtf的标准不认得它。
我折腾了一下,写了个小工具把rtf文件的UTF-8转成Word能够认识的Unicode编码。用法很简单,把这个脚本保存为一个.vbs文件,然后把Stata导出的rtf文件拖到这个vbs文件的图标上,它就会生成一个加了后缀“_c”的rtf文件,乱码消失不见。理论上这个小工具也能解决日文、韩文等其它多字节编码问题。
另外顺便解决了表格太宽、超出页面范围的问题,并把样式改得更符合论文习惯,如图:
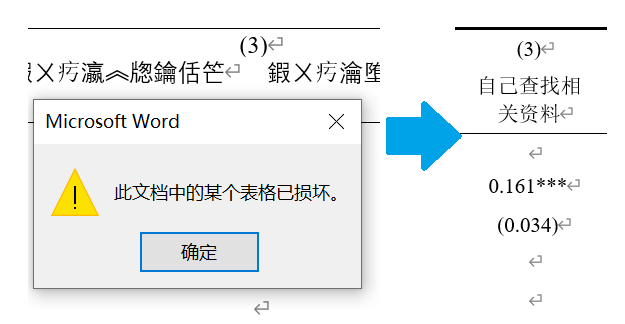
这段代码是匆匆写就的,效率低且丑,欢迎修改。
'Purpose: Encode rtf file containing Multi-byte-char into Unicode format, which is readable in Word.
' A new rtf file with surfix _c will be generated in the same directory of the original file.
'Usage: Drag and drop your RTF file onto this script. Windows XP or above is required.
'Contact: https://wolfccb.com
Set objArgs = WScript.Arguments
if objArgs.Count=0 then
msgbox "Please drag and drop your RTF file onto this script."
Set objArgs=Nothing
WScript.Quit
end if
filename=objArgs (0)
Set stream = CreateObject("ADODB.Stream")
stream.Type = 2 ' adTypeText
stream.Charset = "utf-8"
stream.Open
stream.LoadFromFile filename
txt = stream.ReadText
Set stream=Nothing
txt = Multi_Encode(txt)
'Some extra format settings to meet publication style.
txt = modLine(txt)
txt = replace(txt,"\fs24","\fs21{\fonttbl{\f0\fbidi \froman\fcharset0\fprq2{\*\panose 02020603050405020304}Times New Roman;}{\f13\fbidi \fnil\fcharset134\fprq2{\*\panose 02010600030101010101}\'cb\'ce\'cc\'e5{\*\falt SimSun};}}\f13\f0\sb60\sa60\")
txt = replace(txt,"\trowd","\trowd\trautofit1")
Set fso = CreateObject("Scripting.FileSystemObject")
fileout = replace (filename,".rtf","_c.rtf")
Set f = fso.OpenTextFile(fileout, 2, true)
f.Write txt
f.Close
Set f=Nothing
Set fso=Nothing
Function convert(s)
For i = 1 To Len(s)
if mid(s,i,2)="%E" then
t0=mid(s,i,9)
t1=DecodeUTF8(t0)
s=replace (s,t0,t1)
end if
Next
convert=s
End Function
Function Multi_Encode(ByVal str)
Dim i
Dim code
For i = 1 To Len(str)
code = Mid(str, i, 1)
If Asc(code) < 0 Then
code = Hex(Asc(code))
If Len(code) = 1 Then
code = "0" & code
End If
If CByte("&H" & Right(code, 2)) < 127 Then
code = "\'" & Left(code, 2) & Chr(CByte("&H" & Right(code, 2)))
Else
code = "\'" & Left(code, 2) & "\'" & Right(code, 2)
End If
End If
Multi_Encode = Multi_Encode & code
Next
End Function
Function modLine(s)
start=instr(1,s,"\row")
endto=instrrev(s,"\trowd",-1)
temp1=mid(s,1,start)
temp2=mid(s,start+1,endto-start+1)
temp3=mid(s,endto,len(s))
temp1=replace(temp1,"\brdrs","\brdrs\brdrw30")
temp3=replace(temp3,"\brdrs","\brdrs\brdrw30")
modLine=temp1 & temp2 & temp3
End Function
以上。
重复造轮子的老狼
求问将rtf文件拖拽到vbs文件上后显示文件无法被打开是什么原因呢!谢谢博主!
我用着一直正常啊,你是windows系统吗?这个程序不支持Mac
感谢您的脚本,非常好用。顺便问一下,有办法处理多个文件吗?因为我一导出就很多doc文件
您可以再写一个脚本调用它,用vbs就行。